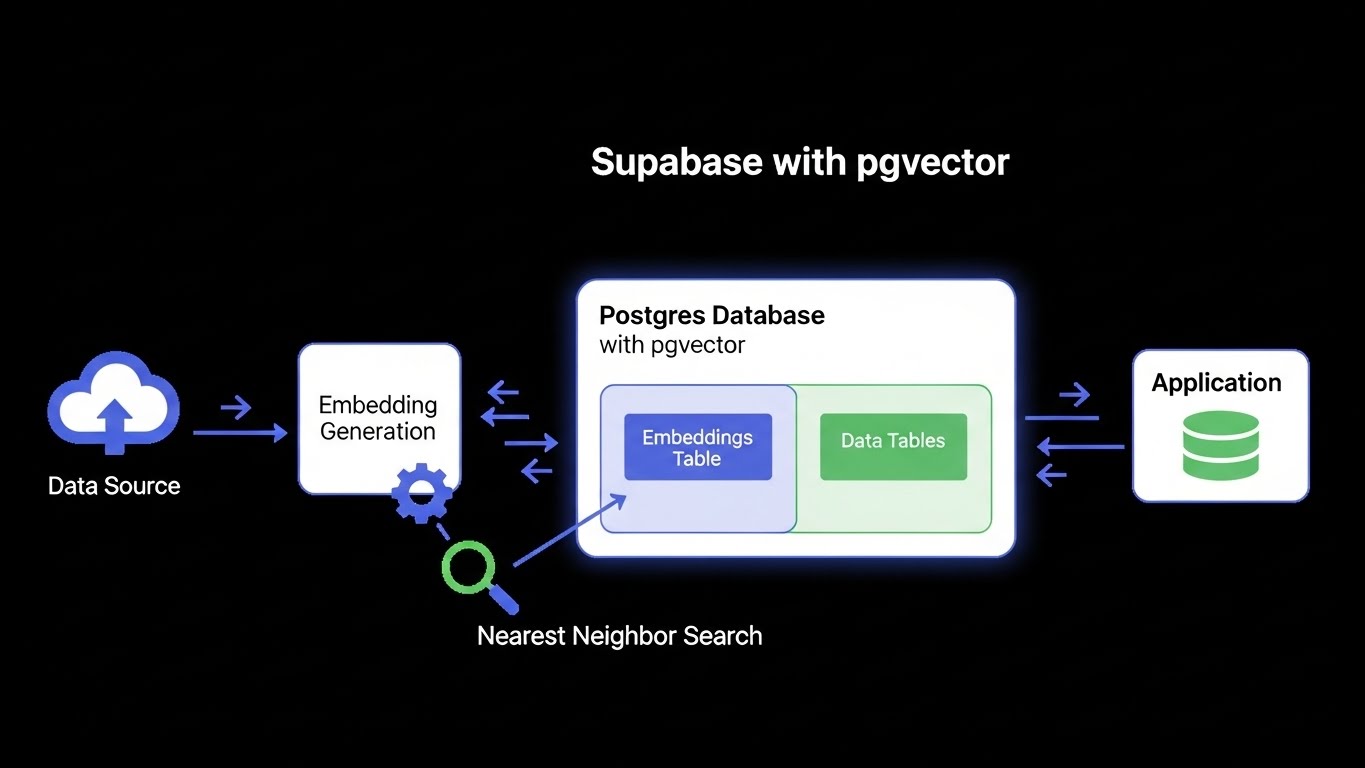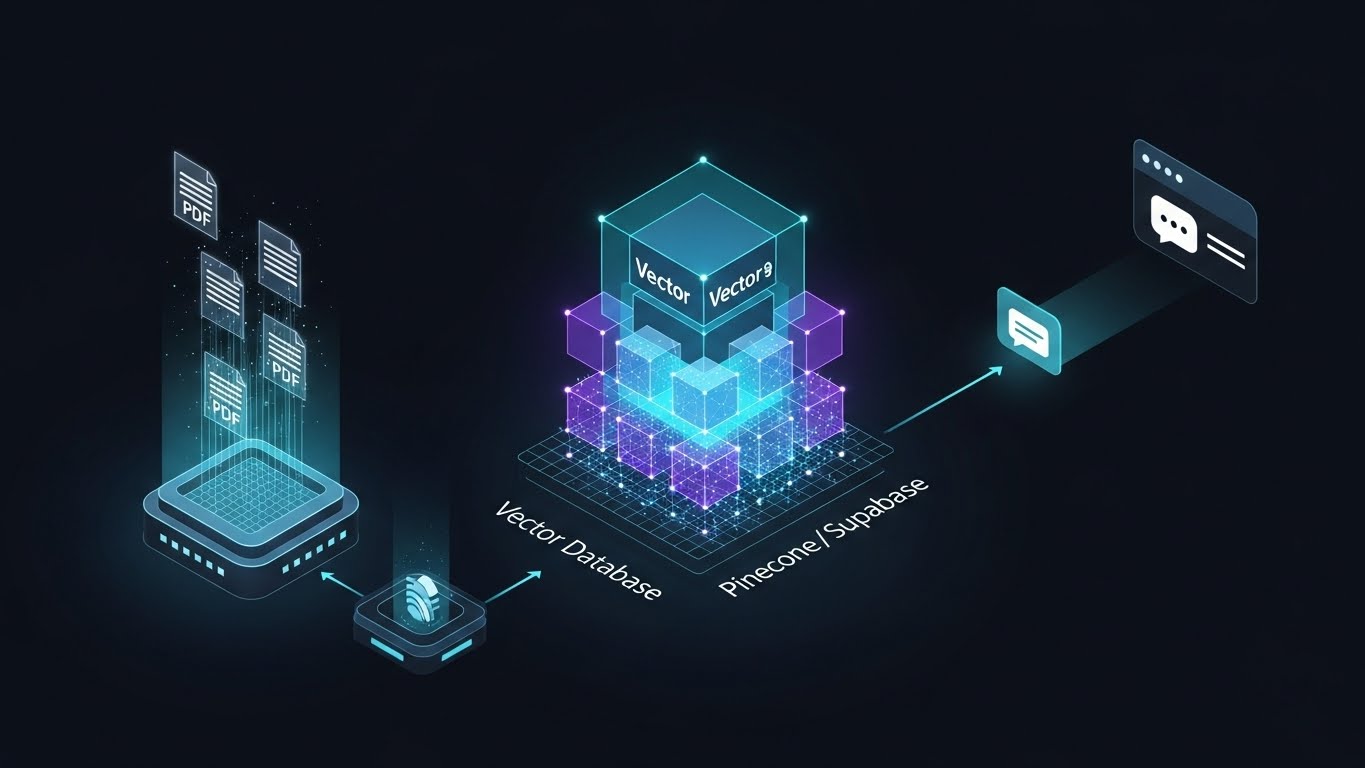
The Ingestion Layer
The architecture begins with a Python-based ingestion script that acts as the "Gatekeeper." It parses raw PDF, Notion, and Text documents, cleaning the noise before splitting the content into semantic chunks of 500 tokens.
These chunks are processed through OpenAI's text-embedding-3-small model, converting human language into high-dimensional vector arrays that represent the meaning rather than just the keywords.