Problem
The editorial team relied on manual copying, cleanup, and categorization of news articles. This resulted in duplicate content, inconsistent formatting, slow turnaround times, and high cognitive load for editors.
Solution
I designed an automated editorial pipeline using n8n that scrapes articles from multiple sources, resolves redirect links, cleans the content, removes duplicates using UUID checks, and structures the output into AI-ready drafts.
Result
The system reduced manual editorial work by over 80%, eliminated duplicate entries, standardized article structure, and enabled editors to focus purely on review and decision-making instead of data preparation.
System Architecture
The pipeline starts by regularly scraping selected news sources and RSS feeds, then consolidating everything into a single intake so editors no longer juggle multiple tabs or exports. Each story is normalized, with redirects resolved so tracking is tied to the real canonical URL, not temporary or shortened links. A unique UUID is attached to every article, preventing duplicates and giving downstream systems a stable reference for logs and analytics.
Behind this, the system is organized into modular services for fetching, parsing, enrichment, and storage instead of one monolithic script. That separation makes it easy to plug in new feeds, swap parsers, or update rules without breaking the whole pipeline. It also creates clear handoff points, so issues are easier to debug and performance bottlenecks are easier to spot.
All processed content flows into a structured data store that exposes consistent fields like source, topic, entities, and publication time. Editors and downstream tools can then filter and route content using this clean metadata rather than brittle text searches. The result is a predictable content backbone that supports dashboards, search, and future automation work with minimal rework.
Automation Logic
Once content is ingested, it is broken into clear blocks—headline, summary, body, entities, and metadata—so automation can target specific pieces instead of treating an article as raw text. Rules handle tasks like language detection, category assignment, and basic quality checks before any AI is applied. This keeps noisy or off‑topic items from flowing further into the system.
AI is used selectively where it adds obvious value: generating concise summaries, cleaning up structure, and suggesting tags or angles. It is not used as a black box decision‑maker; guardrails and business rules still define what gets published and how. Editors retain control over final wording, framing, and standards, with AI acting as an assistant rather than a replacement.
After processing, enriched articles are written into a structured dashboard view for the editorial team. Each row represents a story with its summary, tags, and key metrics ready for quick scanning. Editors can accept, tweak, or discard AI suggestions in a few clicks, keeping the workflow fast without sacrificing oversight.
Editorial Impact
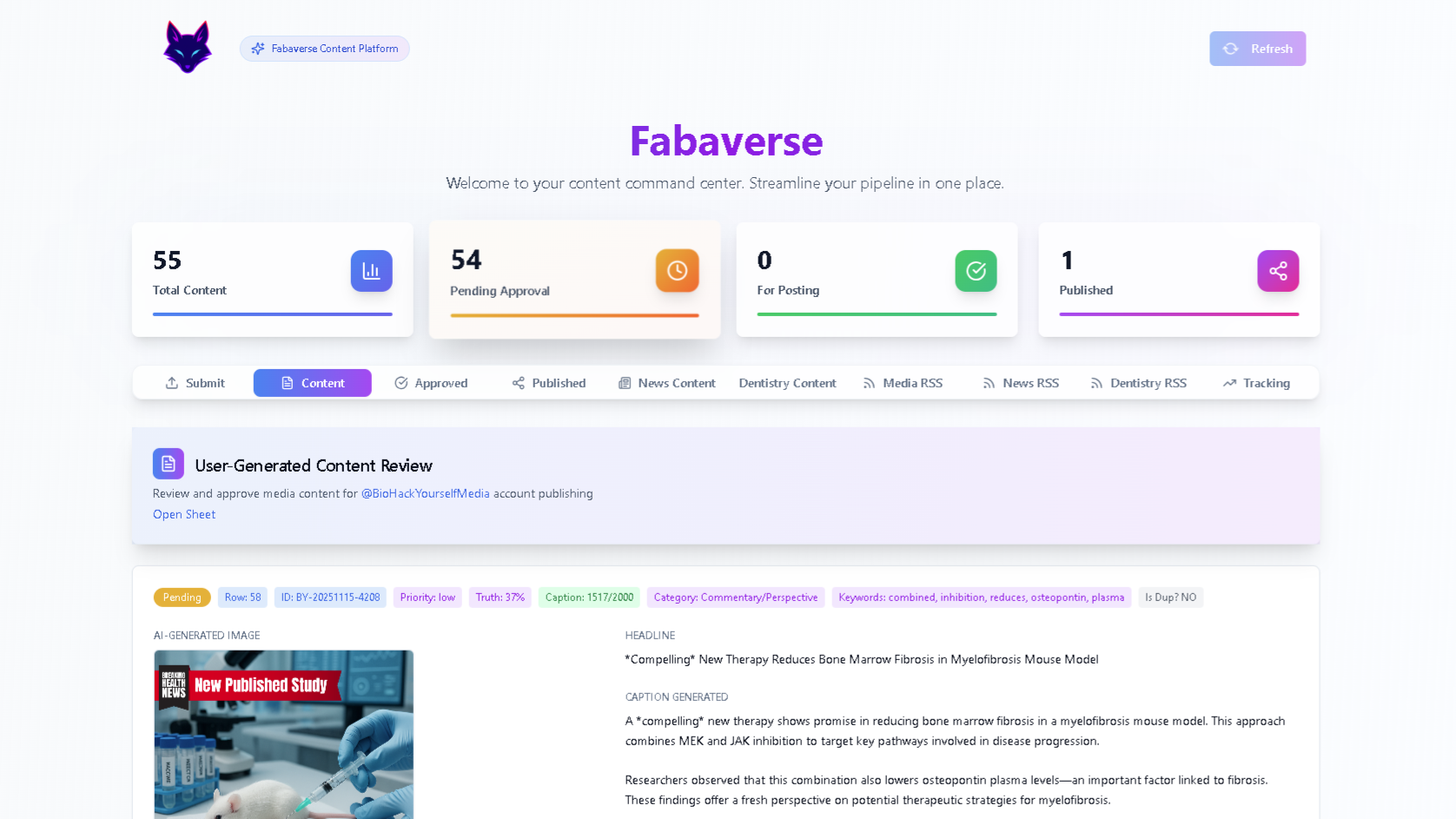
For editors, the biggest change is that every draft now arrives pre‑cleaned, summarized, and tagged instead of as messy copy that needs heavy manual work. Routine tasks like fixing URLs, reformatting text, and creating short abstracts are handled before a human even opens the story. This shifts time toward judgment calls—angle, context, and verification—rather than repetitive production chores.
Because the pipeline preserves raw source data alongside structured outputs, articles can be regenerated in different formats without redoing the entire process. Editors can request shorter briefs, alternative headlines, or new angles and have them produced quickly from the same underlying record. This makes experimentation with new sections, newsletters, or regional editions far less risky.
The overall effect is a calmer, more scalable editorial operation where teams can handle more stories with the same headcount. New beats or sources are added by configuring feeds and rules instead of building parallel, manual workflows. The system gives the newsroom a repeatable way to grow coverage while keeping quality and brand voice under editorial control.
← Back to Case Studies 